
En términos de conocimiento, los expertos en ciencia de datos esperan mucho: aprendizaje automático, programación, estadísticas, matemáticas, visualización de datos, comunicación y aprendizaje profundo. Cada una de estas áreas cubre docenas de idiomas, marcos, tecnologías disponibles para el estudio.
Entonces, ¿Cómo gestionan los científicos de datos su tiempo de capacitación, para que valga el precio que estén dispuestos a pagar los empleadores?
Al respecto, hemos hecho un análisis cuidadoso de los sitios de trabajo, para averiguar qué habilidades son ahora más populares entre los empleadores. Analizamos las disciplinas más amplias relacionadas con el trabajo con datos y los idiomas, así como herramientas específicas en un estudio separado.
Además, hemos estudiado muchas descripciones de trabajo y encuestas, para comprender qué habilidades se mencionan con mayor frecuencia. Los términos como «administración» no se incluyeron en el análisis, ya que se utilizan en una amplia gama de contextos diversos en los sitios de trabajo.
La búsqueda se realizó en los Estados Unidos según los términos «cientifico de datos». Para reducir el problema, seleccionamos solo las palabras claves exactas. De todos modos, el método similar garantizó que todos los resultados serán relevantes para la ciencia de datos y se aplicarán los mismos criterios a todas las solicitudes.
AngelList no proporciona el número total de trabajos relacionados con el trabajo con datos, sino el número total de empresas que ofrecen dichos trabajos. Excluí este sitio de ambos estudios, ya que su algoritmo de búsqueda, aparentemente, funciona según el principio de «OR» y no permite cambiar de alguna manera al modelo «AND». Puede trabajar con AngelList cuando ingresa algo en el espíritu del «científico de datos», «TensorFlow»: en este caso, el cumplimiento de la segunda solicitud supone el cumplimiento de la primera. Sin embargo, si utiliza palabras clave en el espíritu de «científico de datos», «reaccion.js», habrá muchas vacantes en trabajos que no sean de ciencia de datos.
Los materiales con Glassdoor también tuvieron que ser excluidos. El sitio afirmó que tenía información sobre 26 263 vacantes para trabajar con datos, pero de hecho, se mostró un máximo de 900. Además, me parece extremadamente dudoso que hayan acumulado más de tres veces más vacantes que cualquier otro sitio importante.
Para la etapa final de la investigación, seleccioné las palabras clave para las que LinkedIn tenía un gran problema: más de 400 resultados para habilidades generales, más de 200 para tecnologías privadas. Por supuesto, no hubo ofertas duplicadas. Grabé los resultados de esta etapa en el documento de Google.
Luego descargué los archivos en formato .csv, los subí a JupyterLab, calculé la tasa de prevalencia de cada uno en porcentaje y promedié los valores obtenidos para diferentes recursos. Posteriormente comparé los resultados en idiomas con los informados en el estudio para las vacantes de datados de Glassdoor en el primer semestre de 2017. Si agrega a esta información de la encuesta sobre el uso de KDNuggets, parece que algunas habilidades están ganando popularidad, mientras que otras están perdiendo valor gradualmente. Pero más sobre eso más tarde.
En mi Kaggle Kernel encontrarás gráficos interactivos y análisis adicionales. Para la visualización, utilicé Plotly. Para trabajar en conjunto con Plotly y JupyterLab, debes podshmanat algo, al menos fue en el momento de escribir esto: puedes leer las instrucciones al final de mi Kaggle Kernel, así como en la documentación de Plotly.
Índice
Habilidades generales
Aquí hay un gráfico que representa las habilidades generales más populares que los empleadores quieren ver de los candidatos.
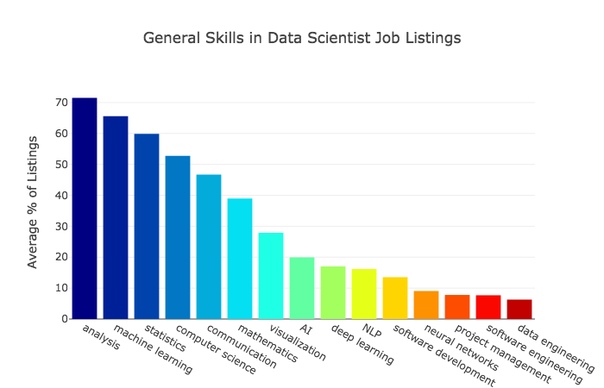
Los resultados muestran que los análisis y el aprendizaje automático siguen siendo la base del trabajo de los científicos de datos. El propósito principal de esta especialidad es sacar conclusiones útiles basadas en matrices de datos. El aprendizaje automático apunta a crear sistemas que puedan predecir el curso de los eventos, respectivamente, que tiene una gran demanda.
El procesamiento de datos requiere conocimiento de estadísticas y la capacidad de escribir código, no hay nada sorprendente. Además, las estadísticas, las matemáticas y la ingeniería de software son especialidades que se están capacitando en las universidades y que también pueden afectar la frecuencia de las consultas.
Curiosamente, en las descripciones de casi la mitad de las vacantes, se menciona la comunicación: los administradores de datos deben poder comunicar sus hallazgos y trabajar en equipo a las personas.
Las referencias a la IA y el aprendizaje profundo no son tan regulares como algunas otras solicitudes. Sin embargo, estas áreas son ramas de aprendizaje automático. El aprendizaje profundo se usa cada vez más en tareas para las cuales se utilizaron previamente algoritmos de aprendizaje automático. Por ejemplo, los mejores algoritmos de aprendizaje automático para problemas que surgen en el procesamiento del lenguaje natural ahora pertenecen específicamente al campo del aprendizaje profundo. Creo que en el futuro se volverá más y más popular, y el aprendizaje automático comenzará a percibirse gradualmente como un sinónimo de lo profundo.
¿Qué soluciones de software específicas deben dominar los expertos en ciencia de datos, según los empleadores? Pasamos a este tema en la siguiente sección.
Habilidades tecnologicas
A continuación se presentan 20 idiomas específicos, bibliotecas y herramientas tecnológicas con los que, en opinión de los empleadores, los especialistas en procesamiento de datos deben tener experiencia.
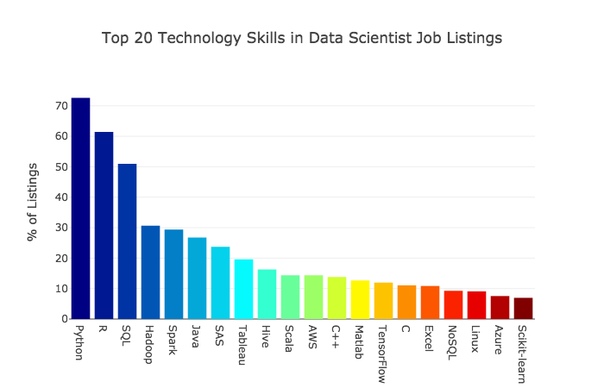
Vayamos rápidamente a través de los líderes.

Python es la opción más popular. El hecho de que este lenguaje de código abierto es extremadamente popular entre los programadores, es conocido por muchos. Para los principiantes, esta es una opción muy conveniente: hay muchos recursos de aprendizaje. La gran mayoría de las nuevas herramientas de datos son compatibles con él. Por todas estas razones, Python puede llamarse el idioma principal para los especialistas en ciencia de datos.

R sigue a Python por un pequeño margen. Una vez, fue él quien fue el idioma principal para los especialistas en ciencia de datos. Me sorprendió que todavía haya un interés activo en él. Este lenguaje se origina en las estadísticas y, por lo tanto, es muy popular entre quienes lo tratan.
Casi todas las vacantes hacen imperativo conocer uno de estos dos idiomas: Python o R.

SQL también es muy popular. La abreviatura significa lenguaje de consulta estructurado (lenguaje de consulta estructurado), y es este lenguaje el que es la herramienta principal para interactuar con bases de datos relacionales. El SQL en la comunidad de la ciencia de datos a menudo se descuida, pero se refiere a habilidades que debe demostrar fluidez si planea ingresar al mercado laboral.


A continuación están Hadoop y Spark, ambas herramientas de código abierto de Apache, diseñadas para trabajar con big data. Sobre ellos mucho menos escritos tutoriales y artículos en medio. Supongo que el número de solicitantes que los poseen es mucho menor que aquellos familiarizados con Python o R. Si puede trabajar con Hadoop y Spark o tiene la oportunidad de dominarlos, esta puede ser una buena ventaja sobre sus competidores.


El siguiente es Java y SAS. Me sorprendió que estos dos idiomas pudieran escalar tan alto. Ambos son descendientes de grandes empresas y ambos presentaron un cierto número de materiales gratuitos. Sin embargo, entre los expertos en ciencia de datos, ni Java ni SAS despiertan mucho interés.

El siguiente en el ranking de tecnologías populares es Tableau. Es una plataforma analítica y una herramienta de visualización, con gran potencia y fácil de usar. Su popularidad está aumentando constantemente. Tableau tiene una versión pública gratuita, pero si desea trabajar con datos en modo privado, tendrá que desembolsar. Si no está familiarizado con Tableau, tiene sentido tomar un curso corto, por ejemplo, Tableau 10 AZ en Udemy. Para la publicidad, no me pagan, solo trabajé en este curso y lo encontré muy útil.
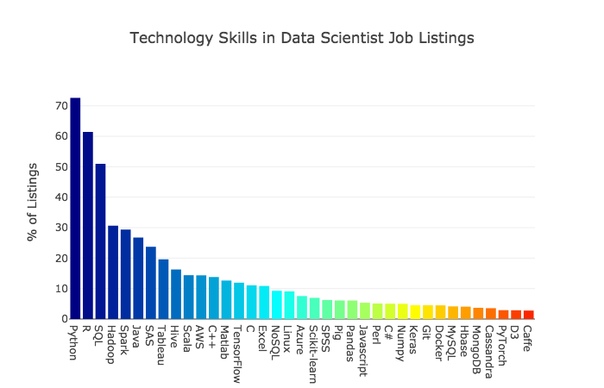
En el gráfico a continuación puede encontrar una lista extendida de lenguajes populares, marcos y otras herramientas para trabajar con datos.
Comparacion historica
El equipo de GlassDoor publicó un estudio de las diez habilidades más populares para los especialistas en ciencia de datos en el período de enero a julio de 2017. En el gráfico a continuación, sus datos sobre la frecuencia de los términos se comparan con los valores promedio calculados por mí para LinkedIn, Indeed, SimplyHired y Monster.
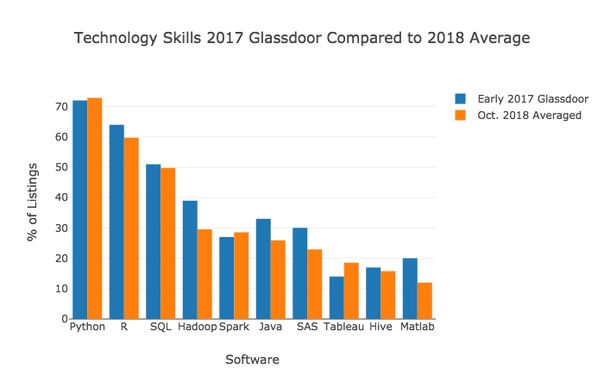
En general, los resultados son similares. Tanto mi investigación como el estudio de Glassdoor coinciden en que la demanda de Python, R y SQL es la más alta. Las mejores habilidades también coinciden en composición dentro de las primeras nueve posiciones, aunque el orden exacto es diferente.
A juzgar por los resultados, en comparación con la primera mitad de 2017, la demanda de R, Hadoop, Java, SAS y MatLab disminuyó, y Tableau, por el contrario, se volvió más popular. Esto era de esperar si observaba al menos los resultados de la encuesta de desarrolladores de KDnuggets. Muestran claramente que R, Hadoop, Java y SAS han estado disminuyendo durante varios años, mientras que Tableau ha ido en constante aumento.
Recomendaciones
Teniendo en cuenta estos cálculos, me gustaría ofrecer una serie de recomendaciones para los especialistas que trabajan con datos que ya han ingresado al mercado o simplemente se están preparando para comenzar una carrera y al mismo tiempo mejorar su competitividad.
- Demuestre que puede analizar los datos y no escatime esfuerzos para aprender cómo aprender el aprendizaje automático.
- Preste atención a las habilidades de comunicación. Le aconsejaría leer el libro «Made to Stick», que describe cómo dar más peso a sus ideas. También practique con la aplicación Hemmingway Editor para aprender a expresar sus pensamientos con mayor claridad.
- Dominar el marco de aprendizaje profundo. Esto se está convirtiendo gradualmente en una parte integral del proceso de aprendizaje. En mi otro artículo comparo varios marcos por lo útiles, interesantes y populares que son, puedes leerlos aquí.
- Si dudas entre Python y R, elige Python. Si ya conoces Python como la palma de tu mano, considera explorar y R. Esto definitivamente te hará un candidato más atractivo en el mercado.
Cuando un empleador busca un empleado que trabaja con Python, lo más probable es que los candidatos se familiaricen con las bibliotecas principales para el procesamiento de datos: numpy, pandas, scikit-learn y matplotlib. Si quieres aprender este kit, te recomiendo los siguientes recursos:
- DataCamp y del CDE – y allí, y no puede haber un poco de dinero para pasar un curso de formación dela ciencia de datos en modo SaaS en línea; Usted aprenderá justo en el proceso de escribir código. Ambos cursos cubren una amplia gama de herramientas.
- Data School ofrece una amplia gama de diferentes recursos, incluida una buena serie de videos en Youtube, donde se explican los conceptos básicos de la ciencia de datos.
- «Python y análisis de datos» McKinney. Este es el trabajo del autor de la biblioteca pandas; básicamente se trata de eso, pero también se ven afectados los conceptos básicos de Python, numpy y scikit-learn en relación con la ciencia de datos.
- “Introducción al aprendizaje automático utilizando Python. Una guía para expertos en datos de Muller y Guido. Müller es responsable del soporte de scikit-learn. Un excelente libro para quienes estudian el aprendizaje automático en general y esta biblioteca en particular.
Si desea hacer un gran avance en el aprendizaje profundo, le aconsejo que comience con Keras o FastAI, y luego vaya a TensorFlow o PyTorch. «Deep learning in Python» de Scholle es una gran ayuda para aquellos que aprenden a trabajar con Keras.
Además de estas recomendaciones, creo que vale la pena concentrarse en estudiar lo que a usted mismo le interesa, aunque, por supuesto, puede distribuir su tiempo de capacitación basado en una variedad de consideraciones.
Si está buscando ofertas de trabajo para trabajar con datos en portales en línea, le aconsejo que comience con LinkedIn, ya que tiene el problema más extenso. Además, al buscar vacantes o colocar currículums en sitios web, las palabras clave desempeñan un papel muy importante. Por ejemplo, en todos los recursos considerados, la solicitud de ciencia de datos produce tres veces más resultados que el científico de datos. Por otro lado, si está interesado solo en las ofertas del científico de datos, es mejor dar preferencia a esta solicitud.
Pero sea cual sea el recurso que elija, recomiendo crear una cartera en línea que demuestre sus habilidades en varias áreas populares; cuanto más haya, mejor. Lo ideal es que un perfil de LinkedIn contenga alguna evidencia de las habilidades de las que está hablando.